这个男的是谁呀?怎么看不够啊?


0
这个男的是谁呀?怎么看不够啊?

真好

这个确实有点性感呀。


短剧女主角


这就是生活


生活

好不好看?



菜市场的风景真美啊。

如果说有一天你的女朋友穿成这样,那么你还乐意让她成为你的女朋友吗?

其实我挺喜欢这样的美女的。


明年可能是AI模型的终局之战,很多模型估计都撑不到明年年中,明年年底基本上很多小公司将会进入倒闭潮,有一部分公司就会被一些巨型公司吞并。
最高杠杆的做法:将「长期可维护性」明确写入规则文件 不要只写“写干净的代码”这类空话。应在 CLAUDE.md 或 .cursorrules 中明确规定: 优先考虑可维护性与可扩展性,而非短期开发速度 禁止引入不必要的抽象 所有改动必须遵循现有的架构模式 每次变更都要主动检查重复代码,并提出重构建议 这类规则文件能让 Agent 长期保持一致的输出风格,是目前公认最有效的实践。
以前大家比的是谁家AI脑子好使,现在比的是谁能让AI干得更漂亮。 什么意思呢? 模型能力:就像一个人的智商。现在各家AI智商都差不多(GPT、Claude、Gemini卷到顶了)。 工作流设计:就像你怎么安排这个聪明人干活。 差距在哪儿? 你把一个高智商AI扔进去,不给流程和规则,它照样干得乱七八糟。 但如果你设计好了: 分阶段工作流:先分析 → 再设计 → 然后编码 → 最后测试,别让它一把梭 验证机制:每干完一步自动检查,错了立刻打回 持续优化Skills:把干得好的套路记下来,下次直接用 结果就是: 同样用Claude,有人错误率40%,有人降到10%——差的不是模型,是工作流。 所以2026年的人已经变了: 以前:我写代码让AI跑 现在:我设计工作流让AI自己跑对
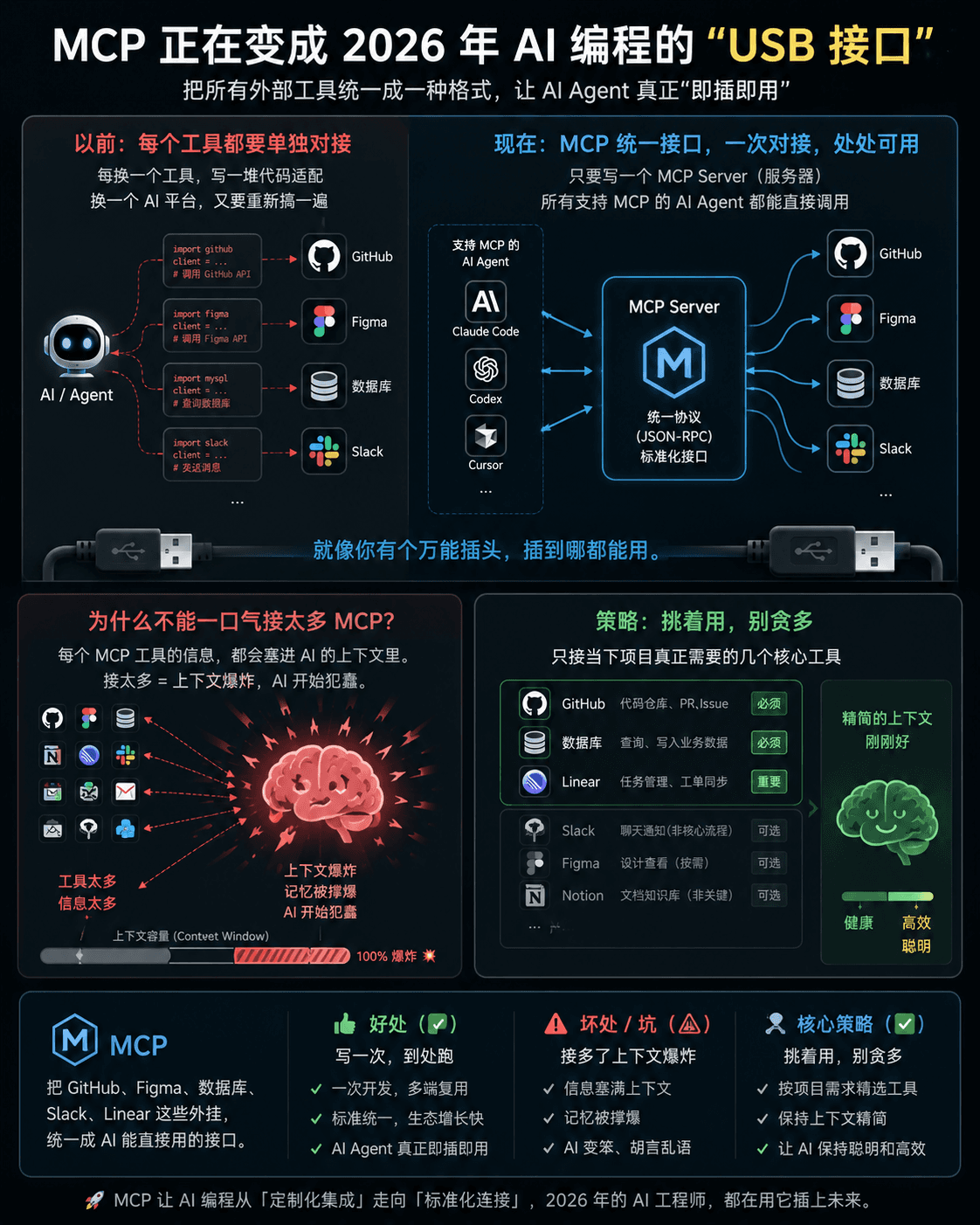
MCP 正在变成 2026 年 AI 编程的“USB 接口”。 以前你想让 AI 帮你查 GitHub、看图、查数据库、发 Slack……每个工具都得单独写代码对接,换一个 AI 平台又要重新搞一遍。 现在 MCP 干了一件事:把所有外部工具统一成一种格式。你只要写一个 MCP Server(服务器),Claude Code、Codex、Cursor 这些 Agent 都能直接调用。 就像你有个万能插头,插到哪都能用。 那现在大家怎么用的? 共识是:别一口气接太多 MCP。 为什么呢?因为每个 MCP 工具的信息都会塞进 AI 的上下文里。接多了上下文直接爆炸(记忆被撑爆,AI 开始犯蠢)。 所以要有选择性地接——只接当下项目真正需要的几个核心工具。 MCP = 把 GitHub、Figma、数据库、Slack、Linear 这些外挂统一成 AI 能直接用的接口 好处:写一次,到处跑 坏处(坑):接多了上下文爆炸 策略:挑着用,别贪多
2026 年 Agent 实战指南:Context Engineering 不要把所有信息堆进一个超长 prompt,而是 动态上下文注入: 长期记忆做成可检索的 Skills / 项目文档 / 历史决策 每次只注入当前任务最相关的 3–5 个 artifacts 用明确标签区分层级:currenttask、relevanthistory、constraints 这样做能明显 降低幻觉、减少 Token 消耗、提高准确率,尤其适合长时任务和复杂项目。
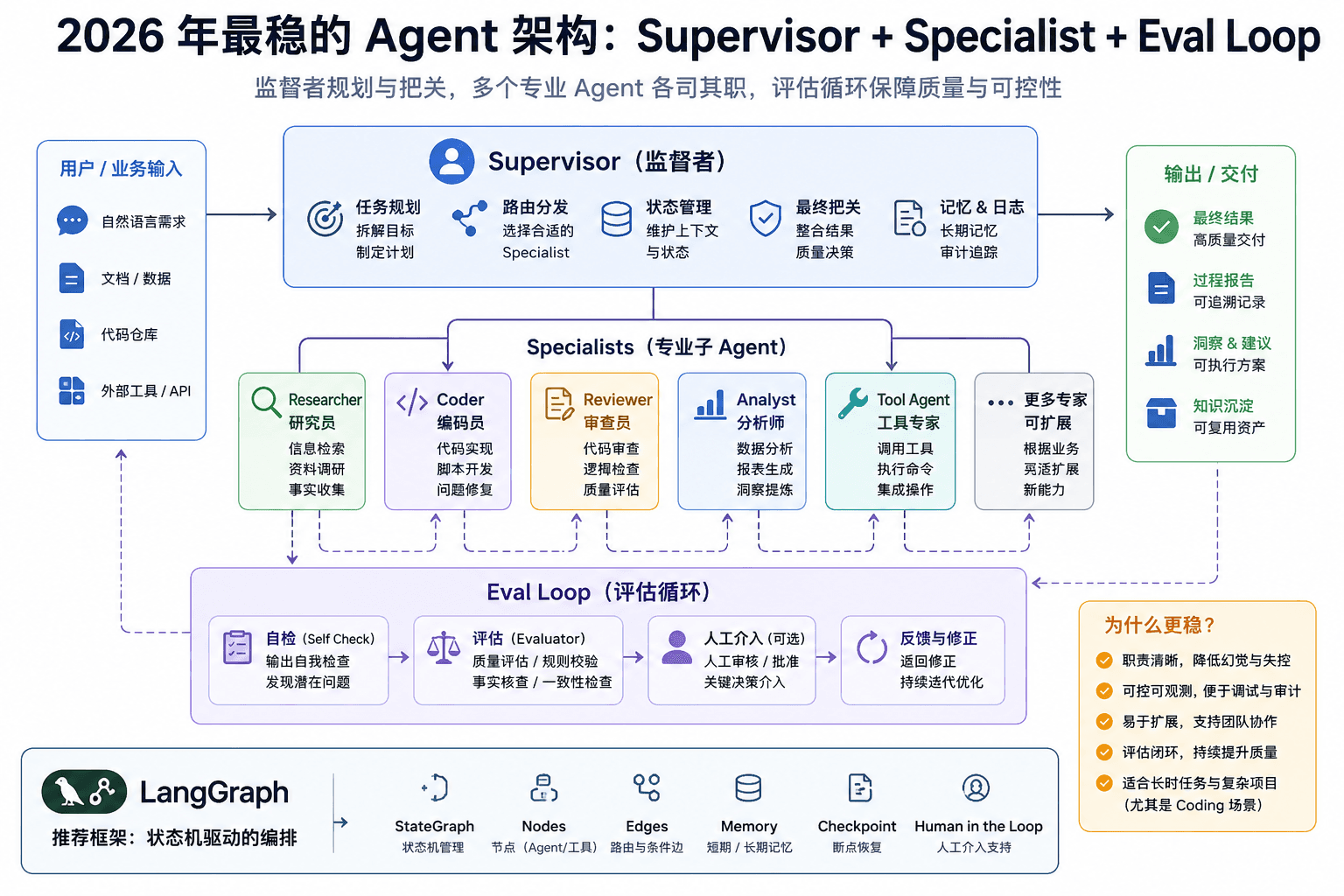
2026 年最稳的 Agent 架构已经不是单个“全能 Agent”了,而是 Supervisor + Specialist + Eval Loop。 一个 Supervisor 负责规划、路由和状态管理,多个 Specialist 只做自己最擅长的事(Research、Coding、Review 等),关键节点再通过 Eval 或人工审核兜底。 生产环境里,这套架构比完全自主 Agent 更稳定、更可控,也更容易扩展。复杂 Coding 和长流程任务尤其明显。LangGraph 这类状态机框架正在成为主流选择。 #AIAgents #LangGraph
. Claude 做 Agent/Coding 的核心打法(当前最强实践) 任何复杂任务必须先走 Plan Mode:让模型输出详细实施计划 + 风险点 + 验收标准,确认后再执行。 项目根目录放 CLAUDE.md(或同等规则文件),把技术栈约束、编码规范、常见坑、输出风格持久化。 重度使用 XML 结构化标签 + 显式 Self-Critique 步骤。 把任务拆成「规划 → 审批 → 分步执行 → 审查」多轮,而不是一口气写完。
这次 Claude Code 的 RCE 风险,表面看是一个 deeplink 漏洞,实质上是一个更大的企业软件问题:当 AI 编程工具既能读代码、改文件、跑命令,又被浏览器、Slack、文档、告警系统用链接唤起时,它就不再只是“助手”,而是本地机器上的半自动执行层。 攻击者可以诱导用户点击一个特制的 claude-cli://open 链接,把恶意配置塞进 Claude Code 启动参数里,最终通过 hooks 执行本地命令。 但这里有个细节要校正一下。DevOps写到“version 2.1.118 的漏洞已修复”容易让人以为 2.1.118 是受影响版本。研究者 0day.click 的原文 说法更明确:这个问题“fixed since Claude Code version 2.1.118”,也就是 2.1.118 起已经修掉。Anthropic 的 Claude Code changelog 显示 2.1.118 发布于 2026 年 4 月 23 日;截至 2026 年 5 月 22 日,changelog 最新版本已经到 2.1.149。 我更关心的是,这不是一个“模型胡说八道导致攻击”的故事。它更像传统 CLI、URL handler、参数解析、配置注入这些老问题,穿上了 AI agent 的外衣。 问题出在一个提前解析参数的逻辑上。Claude Code 的 deeplink 本来是为了方便协作:你可以在 runbook、告警、README 或内部文档里放一个 claude-cli://open 链接,一点就打开本地 Claude Code,并预填某个 repo 和 prompt。Anthropic 官方 deep links 文档 也说明,这类链接会在本机打开 Claude Code,会选择目录,并把 prompt 填进输入框。 安全边界本来应该是:链接只负责“预填”,不负责“执行”。官方文档还写得很清楚,deep link 不应该自己执行任何东西,用户需要看完预填内容再按 Enter。 可研究者发现,参数解析器把本该作为 prompt 内容的一段 --settings=... 当成了真正的启动配置。于是攻击者可以把 hooks 配置塞进去。Claude Code 的 hooks 文档 又明确说明,hooks 可以在 SessionStart、PreToolUse、PostToolUse 等生命周期节点自动运行命令。两件事连起来,风险就变味了:一个“打开工具并预填 prompt”的链接,可能变成“打开工具并自动执行命令”的入口。 这类漏洞对企业尤其麻烦,因为它不需要攻击 AI 模型本身。它攻击的是 AI 工具周边的胶水层:URL scheme、CLI parser、settings、hooks、workspace trust、permission mode。换句话说,安全团队过去盯的是模型输出,现在还得盯模型运行环境。 还有一个更现实的点:很多团队正在把 AI coding agent 接进 CI、IDE、Slack、工单、告警系统。链接、插件、hooks、MCP、权限模式,本来都是为了提效。可提效链路越顺滑,攻击面也越像自动化流水线。一次点击、一个已信任 repo、一段被提前解析的配置,就可能绕过“人会看一眼”的假设。 这也解释了为什么我不把它看成单个产品的丑闻。Claude Code 官方安全页强调默认只读、执行命令要权限、可以用 sandbox 和 permissions 控制边界;这些设计方向没错。但这次事件提醒我们:只要 agent 能运行本地命令,真正的安全边界不能只放在 agent 自己的解释逻辑里。配置加载顺序、参数上下文、URL handler 行为、hooks 来源,都必须当成高风险入口审计。 对企业用户,短期动作很简单:升级到 2.1.118 或更高版本,最好直接跟进到当前最新稳定版本;检查内部文档、runbook、Slack bot、告警平台里是否已经使用 claude-cli:// 链接;对 hooks 做清单化管理,尤其是 SessionStart 这类一开会话就运行的钩子;不要把外部来源的 deeplink 当成普通网页链接点。 更重要的是中长期动作:把 AI 编程工具当成“有本地执行能力的开发基础设施”,而不是普通 SaaS。普通 SaaS 出问题,多半是数据泄漏或权限越界;本地 coding agent 出问题,可能直接碰到源码、密钥、SSH 配置、构建脚本、云账号上下文。 这件事的反直觉之处在于,越专业的团队越可能受影响。因为他们更可能用 hooks 自动跑测试、自动格式化、自动开工单、自动接告警;他们也更可能把 deeplink 放进运维流程里。个人用户可能只是点开聊天,企业用户点开的可能是一条半自动化生产链。 所
